Explainer: What is a File System?
Have you ever needed to format a new hard drive or USB drive, and were given the option of selecting from acronyms like FAT, FAT32, or NTFS? Or did you once try plugging in an external device, only for your operating system to have trouble understanding it? Here's another one... do you sometimes simply get frustrated by how long it takes your OS to find a particular file while searching?
If you have experienced any of the above, or simply just pointed-and-clicked your way to find a file or application on your computer, then you've had first-hand experience into what a file system is.
Many people might not employ an explicit methodology for organizing their personal files on a PC (explainer_file_system_final_actualfinal_FinalDraft.docx). However, the abstract concept of organizing files and directories for any device with persistent memory needs to be very systematic when reading, writing, copying, deleting, and interfacing with data. This job of the operating system is typically assigned to the file system.

There are many different ways to organize files and directories. If you can simply imagine a physical file cabinet with papers and folders, you would need to consider many things when coming up with a system for retrieving your documents. Would you organize the folders in alphabetical, or reverse alphabetical order? Would you prioritize commonly accessed files in the front or back of the file cabinet? How would you deal with duplicates, whether on purpose (for redundancy) or accidental (naming two files exactly the same way)? These are just a few analogous questions that need answering when developing a file system.
In this explainer, we'll take a deep dive into how modern day computers tackle these problems. We'll go over the various roles of a file system in the larger context of an operating system and physical drives, in addition to how file systems are designed and implemented.
Persistent Data: Files and Directories
Modern operating systems are increasingly complex, and need to manage various hardware resources, schedule processes, virtualize memory, among many other tasks. When it comes to data, many hardware advances such as caches and RAMs have been designed to speed up access time, and ensure that frequently used data is "nearby" the processor. However, when you power down your computer, only the information stored on persistent devices, such as hard disk drives (HDDs) or solid-state storage devices (SSDs), will remain beyond the power off cycle. Thus, the OS must take extra care of these devices and the data onboard, since this is where users will keep data they really care about.

Two of the most important abstractions developed over time for storage are the file and the directory. A file is a linear array of bytes, each of which you can read or write. While at the user space we can think of clever names for our files, underneath the hood there are typically numerical identifiers to keep track of file names. Historically, this underlying data structure is often referred to as its inode number(more on that later). Interestingly, the OS itself does not know much about the internal structure of a file (i.e., is it a picture, video, or text file); in fact, all it needs to know is how to write the bytes into the file for persistent storage, and make sure it can retrieve it later when called upon.
The second main abstraction is the directory. A directory is actually just a file underneath the hood, but contains a very specific set of data: a list of user-readable names to low-level name mappings. Practically speaking, that means it contains a list of other directories or files, which altogether can form a directory tree, under which all files and directories are stored.
Such an organization is quite expressive and scalable. All you need is a pointer to the root of the directory tree (physically speaking, that would be to the first inode in the system), and from there you can access any other files on that disk partition. This system also allows you to create files with the same name, so long as they do not have the same path (i.e., they fall under different locations in the file-system tree).

Additionally, you can technically name a file anything you want! While it is typically conventional to denote the type of file with a period separation (such as .jpg in picture.jpg), that is purely optional and isn't mandatory. Some operating systems such as Windows heavily suggest using these conventions in order to open files in the respective application of choice, but the content of the file itself isn't dependent on the file extension. The extension is just a hint for the OS on how to interpret the bytes contained inside a file.
Once you have files and directories, you need to be able to operate on them. In the context of a file system, that means being able to read the data, write data, manipulate files (delete, move, copy, etc.), and manage permissions for files (who can perform all the operations above?). How are modern file systems implemented to allow for all these operations to happen quickly and in a scalable fashion?
File System Organization
When thinking about a file system, there are typically two aspects that need to be addressed. The first is the data structures of the file system. In other words, what types of on-disk structures are used by the file system to organize its data and metadata? The second aspect is its access methods: how can a process open, read, or write onto its structures?
Let's begin by describing the overall on-disk organization of a rudimentary file system.
The first thing you need to do is to divide your disk into blocks. A commonly used block size is 4 KB. Let's assume you have a very small disk with 256 KB of storage space. The first step is to divide this space evenly using your block size, and identify each block with a number (in our case, labeling the blocks from 0 to 63):

Now, let's break up these blocks into various regions. Let's set aside most of the blocks for user data, and call this the data region. In this example, let's fix blocks 8-63 as our data region:
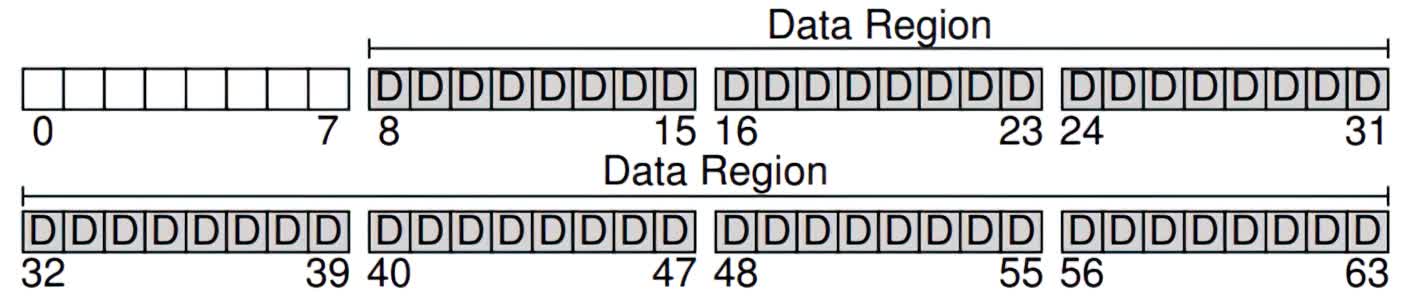
If you noticed, we put the data region in the latter part of the disk, leaving the first few blocks for the file system to use for a different purpose. Specifically, we want to use them to track information about files, such as where a file might be in the data region, how large is a file, its owner and access rights, and other types of information. This information is a key piece of the file system, and is called metadata.
To store this metadata, we will use a special data structure called an inode. In the running example, let's set aside 5 blocks as inodes, and call this region of the disk the inode table:
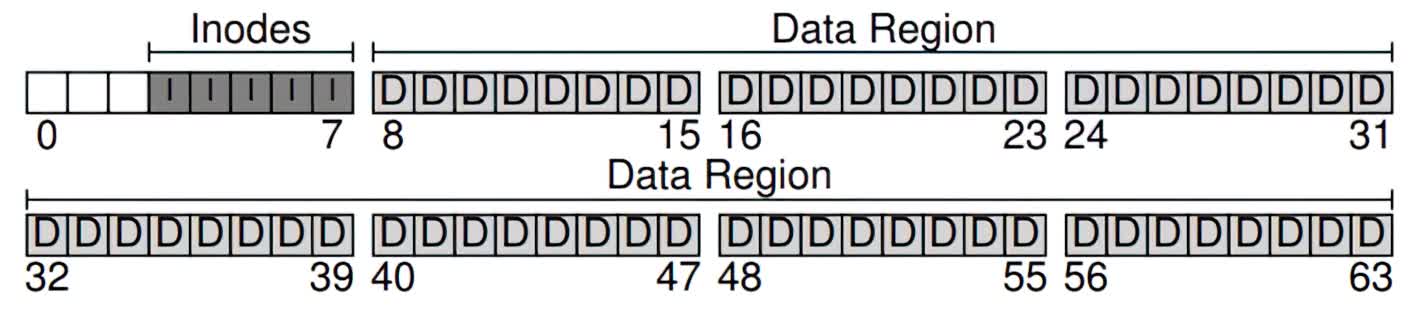
Illustrations borrowed from book: Operating Systems: Three Easy Pieces
Inodes are typically not that big, for example 256 bytes. Thus, a 4KB block can hold about 16 inodes, and our simple file system above contains 80 total inodes. This number is actually significant: it means that the maximum number of files in our file system is 80. With a larger disk, you can certainly increase the number of inodes, directly translating to more files in your file system.
There are a few things remaining to complete our file system. We also need a way to keep track of whether inodes or data blocks are free or allocated. This allocations structure can be implemented as two separate bitmaps, one for inodes and another for the data region.
A bitmap is a very simple data structure: each bit corresponds to whether an object/block is free (0) or in-use (1). We can assign the inode bitmap and data region bitmap to their own block. Although this is overkill (a block can be used to track up to 32 KB objects, but we only have 80 inodes and 56 data blocks), this is a convenient and simple way to organize our file system.
Finally, for the last remaining block (which, coincidentally, is the first block in our disk), we need to have a superblock. This superblock is sort of a metadata for the metadata: in the block, we can store information about the file system, such as how many inodes there are (80) and where the inode block is found (block 3) and so forth. We can also put some identifier for the file system in the superblock to understand how to interpret nuances and details for different file system types (e.g., we can note that this file system is a Unix-based, ext4 filesystem, or perhaps an NTFS). When the operating system reads the superblock, it can then have a blueprint for how to interpret and access different data on the disk.
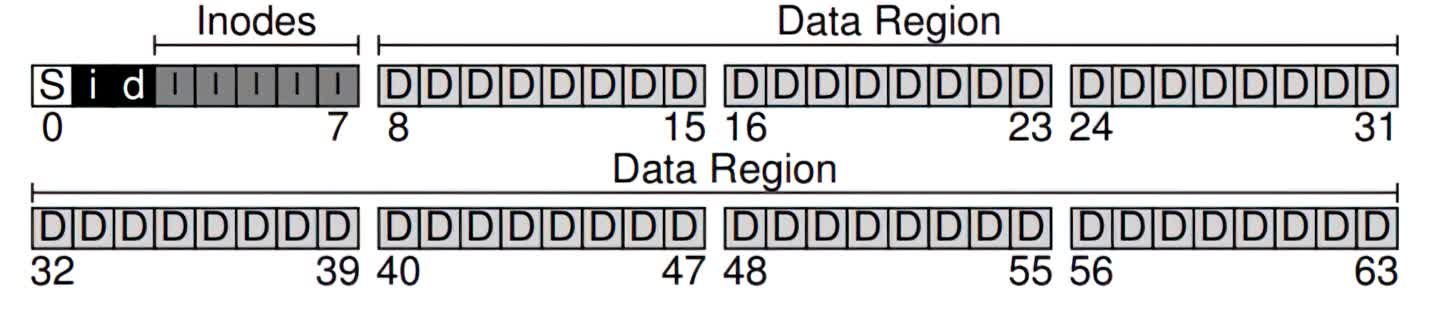
Adding a superblock (S), an inode bitmap (i), and a data region bitmap (d) to our simple system.
The Inode
So far, we've mentioned the inode data structure in a file system, but have not yet explained what this critical component is. An inode is short for an index node, and is a historical name given from UNIX and earlier file systems. Practically all modern day systems use the concept of an inode, but may call them different things (such as dnodes, fnodes, etc).
Fundamentally though, the inode is an indexable data structure, meaning the information stored on it is in a very specific way, such that you can jump to a particular location (the index) and know how to interpret the next set of bits.

A particular inode is referred to by a number (the i-number), and this is the low-level name of the file. Given an i-number, you can look up it's information by quickly jumping to its location. For example, from the superblock, we know that the inode region starts from the 12KB address.
Since a disk is not byte-addressable, we have to know which block to access in order to find our inode. With some fairly simple math, we can compute the block ID based on the i-number of interest, the size of each inode, and the size of a block. Subsequently, we can find the start of the inode within the block, and read the desired information.
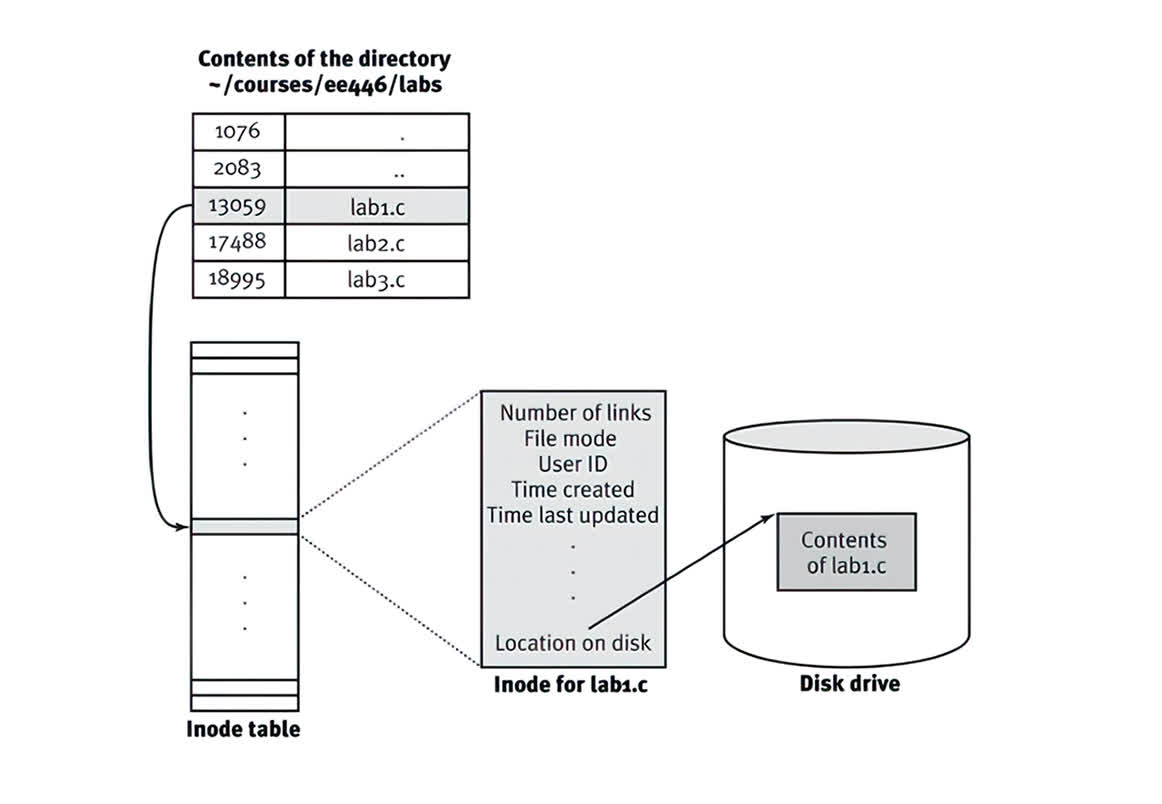
The inode contains virtually all of the information you need about a file. For example, is it a regular file or a directory? What is its size? How many blocks are allocated to it? What permissions are allowed to access the file (i.e., who is the owner, and who can read or write)? When was the file created or last accessed? And many other flags or metadata about the file.
One of the most important pieces of information kept in the inode is a pointer (or list of pointers) on where the data resides in the data region. These are known as direct pointers. The concept is nice, but for very large files, you might run out of pointers in the small inode data structure. Thus, many modern systems have special indirect pointers: instead of directly going to the data of the file in the data region, you can use an indirect block in the data region to expand the number of direct pointers for your file. In this way, files can become much larger than the limited set of direct pointers available in the inode data structure.
Unsurprisingly, you can use this approach to support even larger data types, by having double or triple indirect pointers. This type of file system is known as having a multi-level index, and allows a file system to support large files (think in the gigabytes range) or larger. Common file systems such as ext2 and ext3 use multi-level indexing systems. Newer file systems, such as ext4, have the concept of extents, which are slightly more complex pointer schemes.
While the inode data structure is very popular for its scalability, many studies have been performed to understand its efficacy and extent to which multi-level indices are needed. One study has shown some interesting measurements on file systems, including:
- Most files are actually very small (2KB is the most common size)
- The average file size is growing (almost 200k is the average)
- Most bytes are stored in large files (a few big files use most of the space)
- File systems contain lots of files (almost 100k on average)
- File systems are roughly half full (even as disks grow, files systems remain ~50% full)
- Directories are typically small (many have few entries, 20 or fewer)
This all points to the versatility and the scalability of the inode data structure, and how it supports most modern systems perfectly fine. Many optimizations have been implemented for speed and efficiency, but the core structure has changed little over recent times.
Directories
Under the hood, directories are simply a very specific type of file: they contain a list of entries using (entry name, i-number) pairing system. The entry number is typically a human-readable name, and the corresponding i-number captures its underlying file-system "name."
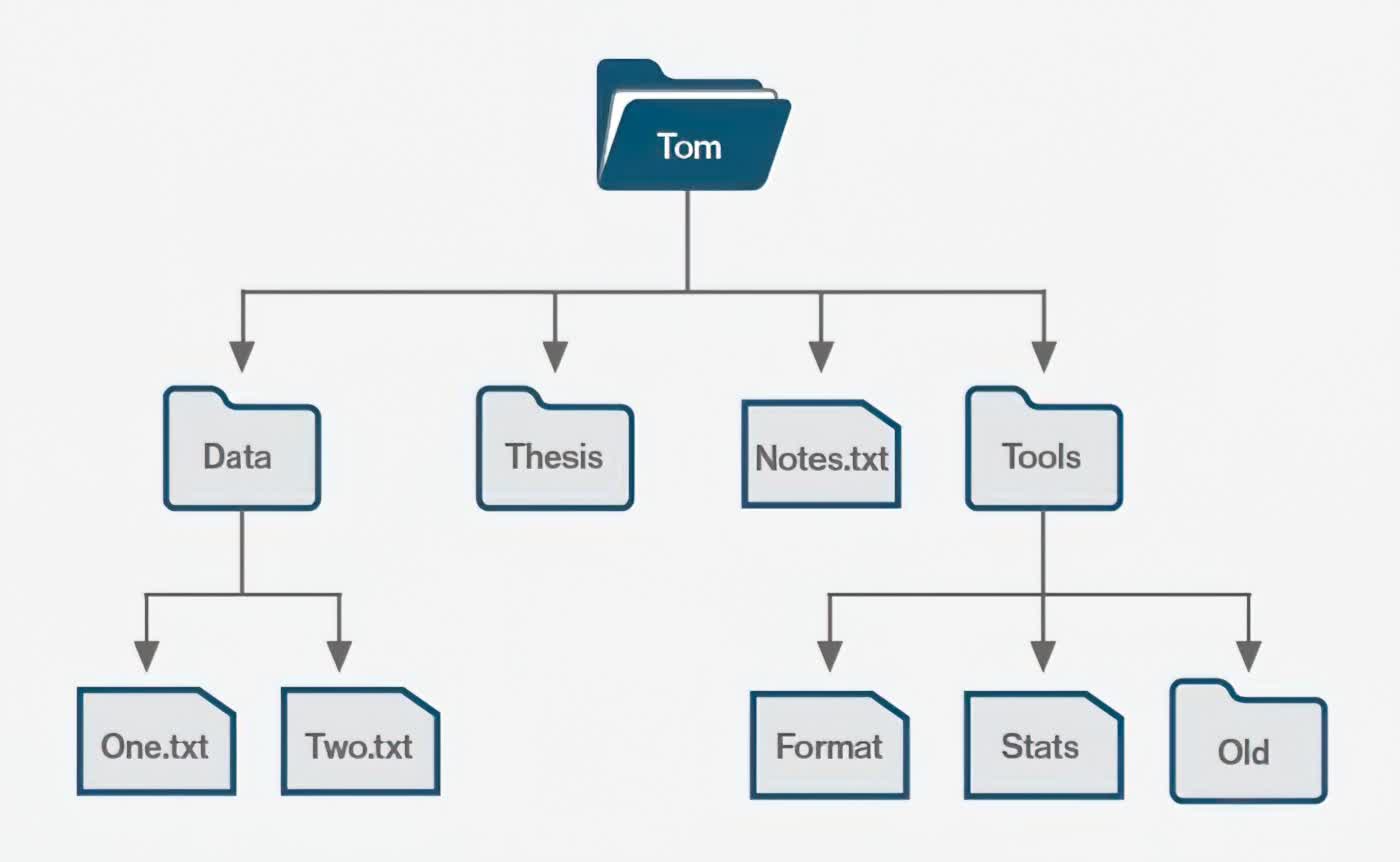
Each directory typically also contains 2 additional entries beyond the list of user names: one entry is the "current directory" pointer, and the other is the parent directory pointer. When using a command line terminal, you can "change directory" by typing
- cd [directory or file name]
or move up a directory by using
- cd ..
where ".." is the abstract name of the parent directory pointer.
Since directories are typically just "special files," managing the contents of a directory is usually as simple as adding and deleting pairings within the file. A directory typically has its own inode in a linear file system tree (as described above), but new data structures such as B-trees have been proposed and used in some modern file systems such as XFS.
Access Methods and Optimizations
A file system would be useless if you could not read and write data to it. For this step, you need a well defined methodology to enable the operating system to access and interpret the bytes in the data region.
The basic operations on a file include opening a file, reading a file, or writing to a file. These procedures require a huge number of input/output operations (I/O), and are typically scattered over the disk. For example, traversing a file system tree from the root node to the file of interest requires jumping from an inode to a directory file (potentially multi-indexed) to the file location. If the file does not exist, then certain additional operations such as creating an inode entry and assigning permissions are required.
Many technologies, both in hardware and software, have been developed to improve access times and interactions with storage. A very common hardware optimization is the use of SSDs, which have much improved access times due to their solid state properties. Hard drives, on the other hand, typically have mechanical parts (a moving spindle) which means there are physical limitations on how fast you can "jump" from one part of the disk to another.
While SSDs provide fast disk accesses, that typically isn't enough to accelerate reading and writing data. The operating system will commonly use faster, volatile memory structures such as RAM and caches to make the data "closer" to the processor, and accelerate operations. In fact, the operating system itself is typically stored on a file system, and one major optimization is to keep common read-only OS files perpetually in RAM in order to ensure the operating system runs quickly and efficiently.
Without going into the nitty-gritty of file operations, there are some interesting optimizations that are employed for data management. For example, when deleting a file, one common optimization is to simply delete the inode pointing to the data, and effectively marking the disk regions as "free memory." The data on disk isn't physically wiped out in this case, but access to it is removed. In order to fully "delete" a file, certain formatting operations can be done to write all zeroes (0) over the disk regions being deleted.
Another common optimization is moving data. As users, we might want to move a file from one directory to another based on our personal organization preferences. The file system, however, just needs to change minimal data in a few directory files, rather than actually shifting bits from one place to another. By using the concept of inodes and pointers, a file system can perform a "move" operation (within the same disk) very quickly.
When it comes to "installing" applications or games, this simply means copying over files to a specific location and setting global variables and flags for making them executable. In Windows, an install typically asks for a directory, and then downloads the data for running the application and places it into that directory. There is nothing particularly special about an install, other than the automated mechanism for writing many files and directories from an external source (online or physical media) into the disk of choice.
Common File Systems
Modern file systems have many detailed optimizations that work hand-in-hand with the operating system to improve performance and provide various features (such as security or large file support). Some of the most popular file systems today include FAT32 (for flash drives and, previously, Windows), NTFS (for Windows), and ext4 (for Linux).
At a high level, all these file systems have similar on-disk structures, but differ in the details and the features that they support. For example, the FAT32 (File Allocation Table) format was initially designed in 1977, and was used in the early days of personal computing. It uses a concept of a linked list for file and directory accesses, which while simple and efficient, can be slow for larger disks. Today, it is a commonly used format for flash drives.
The NTFS (New Technology File System) developed by Microsoft in 1993 addressed many of the humble beginnings of FAT32. It improves performance by storing various additional metadata about files and supports various structures for encryption, compression, sparse files, and system journaling. NTFS is still used today in Windows 10 and 11. Similarly, macOS and iOS devices use a proprietary file system created by Apple, HFS+ (also known as Mac OS Extended) used to be the standard before they introduced the Apple File System (APFS) relatively recently in 2017 and is better optimized for faster storage mediums as well as for supporting advanced capabilities like encryption and increased data integrity.
The fourth extended filesystem, or ext4, is the fourth iteration of the ext file system developed in 2008 and the default system for many Linux distributions including Debian and Ubuntu. It can support large file sizes (up to 16 tebibytes), and uses the concept of extents to further enhance inodes and metadata for files. It uses a delayed allocation system to reduce writes to disk, and has many improvements for filesystem checksums for data integrity, and is also supported by both Windows and Mac.
Each file system provides its own set of features and optimizations, and may have many implementation differences. However, fundamentally, they all carry out the same functionality of supporting files and interacting with data on disk. Certain file systems are optimized to work better with different operating systems, which is why the file system and operating system are very closely intertwined.
Next-Gen File Systems
One of the most important features of a file system is its resilience to errors. Hardware errors can occur for a variety of reasons, including wear-out, random voltage spikes or droops (from processor overclocking or other optimizations), random alpha particle strikes (also called soft errors), and many other causes. In fact, hardware errors are such a costly problem to identify and debug, that both Google and Facebook have published papers about how important resilience is at scale, particularly in data centers.
One of the most important features of a file system is its resilience to errors.
To that end, most next-gen file systems are focusing on faster resiliency and fast(er) security. These features come at a cost, typically incurring a performance penalty in order to incorporate more redundancy or security features into the file system.
Hardware vendors typically include various protection mechanisms for their products such as ECC protection for RAM, RAID options for disk redundancy, or full-blown processor redundancy such as Tesla's recent Fully Self-Driving Chip (FSD). However, that additional layer of protection in software via the file system is just as important.
Microsoft has been working on this problem for many years now in its Resilient File System(ReFS) implementation. ReFS was originally released for Windows Server 2012, and is meant to succeed NTFS. ReFS uses B+ trees for all their on-disk structures (including metadata and file data), and has a resiliency-first approach for implementation. This includes checksums for all metadata stored independently, and an allocation-on-write policy. Effectively, this reduces the burden on administrators from needing to run periodic error-checking tools such as CHKDSK when using ReFS.
In the open-source world, Btrfs (pronounced "better FS" or "Butter FS") is gaining traction with similar features to ReFS. Again, the primary focus is on fault-tolerance, self-healing properties, and easy administration. It also provides better scalability than ext4, allowing roughly 16x more data support.
Summary
While there are many different file systems in use today, the main objective and high-level concepts have changed little over time. To build a file system, you need some basic information about each file (metadata) and a scalable storage structure to write and read from various files.
The underlying implementation of inodes and files together form a very extensible system, which has been fine-tuned and tweaked to provide us with modern file systems. While we may not think about file systems and their features in our day-to-day lives, it is a true testament to their robustness and scalable design which have enabled us to enjoy and access our digital data on computers, phones, consoles, and various other systems.
More Tech Explainers
- What is Crypto Mining?
- What is Chip Binning?
- Explainer: L1 vs. L2 vs. L3 Cache
- What Is a Checksum, and What Can You Do With It?
- Display Tech Compared: TN vs. VA vs. IPS
Masthead image: Jelle Dekkers
本文地址:http://signalforexgratis.com/signal-forex-hari-ini-tanggal-11-mei-2015/
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。